 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-based Schrödinger Bridges for Trustworthy Multimodal Fusion
May 29, 2026Real-world multimodal systems must be robust against low-quality data, such as sensor noise, incomplete multimodal data and conflicting inputs. However, existing trustworthy fusion methods rely on the model's own prediction confidence to judge data quality. This creates a circular dependency: when a model is confident but wrong, these methods fail to detect the error. To break this loop, we propose Geometry-based Multimodal Fusion (GMF). Instead of relying on predictions, we evaluate reliability by measuring how much transport correction the input needs in latent space. We implement Diffusion Schrödinger Bridge transport with Rectified Flow, where the squared initial velocity gives an efficient learned correction score. Valid data has low squared velocity magnitude, while noisy, incomplete data or conflicting data requires stronger transport correction. This geometry-based reliability signal acts as an independent judge, effectively flagging unreliable inputs even when the classifier is fooled. Extensive experiments demonstrate that GMF significantly improves robustness against severe sensor noise and semantic conflicts compared to confidence-based baselines.
Inconsistency-aware Multimodal Schrödinger Bridge for Deepfake Localization
May 22, 2026Audio-visual deepfake localization demands interval-level outputs that serve as temporal evidence. Despite recent progress, symmetric fusion under single-sided or asynchronous forgeries propagates cross-modal noise, degrading high-precision localization. We present IaMSB, an inconsistency-aware multimodal Schrödinger Bridge (SB) that jointly estimates cross-modal consistency and performs interval-level localization. Unlike diffusion models, SB minimizes path-distribution discrepancy and yields consistency scores without explicit noise injection or denoising. With the Schrödinger Bridge (SB), IaMSB unifies consistency estimation, cross-modal information selection, and bridge-step scheduling in one framework. Specifically, a lightweight coarse bridge first proposes candidate intervals and estimates cross-modal consistency; these statistics select cross-modal witness signals and allocate bridge steps asymmetrically across modalities. A refinement bridge then performs step-tuned fusion and outputs refined, time-aligned intervals. IaMSB anticipates single-sided and asynchronous forgeries and, using bottlenecked cross-modal interaction with step allocation, suppresses noise transfer, avoids unnecessary iterations. Across benchmarks, IaMSB stabilizes strict-IoU boundary precision, raising AP@0.95 by 3%~10%, and yields improved high-precision localization, particularly for single-sided forgeries.
When AVSR Meets Video Conferencing: Dataset, Degradation, and the Hidden Mechanism Behind Performance Collapse
Mar 24, 2026Audio-Visual Speech Recognition (AVSR) has achieved remarkable progress in offline conditions, yet its robustness in real-world video conferencing (VC) remains largely unexplored. This paper presents the first systematic evaluation of state-of-the-art AVSR models across mainstream VC platforms, revealing severe performance degradation caused by transmission distortions and spontaneous human hyper-expression. To address this gap, we construct \textbf{MLD-VC}, the first multimodal dataset tailored for VC, comprising 31 speakers, 22.79 hours of audio-visual data, and explicit use of the Lombard effect to enhance human hyper-expression. Through comprehensive analysis, we find that speech enhancement algorithms are the primary source of distribution shift, which alters the first and second formants of audio. Interestingly, we find that the distribution shift induced by the Lombard effect closely resembles that introduced by speech enhancement, which explains why models trained on Lombard data exhibit greater robustness in VC. Fine-tuning AVSR models on MLD-VC mitigates this issue, achieving an average 17.5% reduction in CER across several VC platforms. Our findings and dataset provide a foundation for developing more robust and generalizable AVSR systems in real-world video conferencing. MLD-VC is available at https://huggingface.co/datasets/nccm2p2/MLD-VC.
FastDSAC: Unlocking the Potential of Maximum Entropy RL in High-Dimensional Humanoid Control
Mar 13, 2026Scaling Maximum Entropy Reinforcement Learning (RL) to high-dimensional humanoid control remains a formidable challenge, as the ``curse of dimensionality'' induces severe exploration inefficiency and training instability in expansive action spaces. Consequently, recent high-throughput paradigms have largely converged on deterministic policy gradients combined with massive parallel simulation. We challenge this compromise with FastDSAC, a framework that effectively unlocks the potential of maximum entropy stochastic policies for complex continuous control. We introduce Dimension-wise Entropy Modulation (DEM) to dynamically redistribute the exploration budget and enforce diversity, alongside a continuous distributional critic tailored to ensure value fidelity and mitigate high-dimensional value overestimation. Extensive evaluations on HumanoidBench and other continuous control tasks demonstrate that rigorously designed stochastic policies can consistently match or outperform deterministic baselines, achieving notable gains of 180\% and 400\% on the challenging \textit{Basketball} and \textit{Balance Hard} tasks.
Unifying Speech Editing Detection and Content Localization via Prior-Enhanced Audio LLMs
Jan 29, 2026Speech editing achieves semantic inversion by performing fine-grained segment-level manipulation on original utterances, while preserving global perceptual naturalness. Existing detection studies mainly focus on manually edited speech with explicit splicing artifacts, and therefore struggle to cope with emerging end-to-end neural speech editing techniques that generate seamless acoustic transitions. To address this challenge, we first construct a large-scale bilingual dataset, AiEdit, which leverages large language models to drive precise semantic tampering logic and employs multiple advanced neural speech editing methods for data synthesis, thereby filling the gap of high-quality speech editing datasets. Building upon this foundation, we propose PELM (Prior-Enhanced Audio Large Language Model), the first large-model framework that unifies speech editing detection and content localization by formulating them as an audio question answering task. To mitigate the inherent forgery bias and semantic-priority bias observed in existing audio large models, PELM incorporates word-level probability priors to provide explicit acoustic cues, and further designs a centroid-aggregation-based acoustic consistency perception loss to explicitly enforce the modeling of subtle local distribution anomalies. Extensive experimental results demonstrate that PELM significantly outperforms state-of-the-art methods on both the HumanEdit and AiEdit datasets, achieving equal error rates (EER) of 0.57\% and 9.28\% (localization), respectively.
A Causality-Inspired Model for Intima-Media Thickening Assessment in Ultrasound Videos
Mar 16, 2025Carotid atherosclerosis represents a significant health risk, with its early diagnosis primarily dependent on ultrasound-based assessments of carotid intima-media thickening. However, during carotid ultrasound screening, significant view variations cause style shifts, impairing content cues related to thickening, such as lumen anatomy, which introduces spurious correlations that hinder assessment. Therefore, we propose a novel causal-inspired method for assessing carotid intima-media thickening in frame-wise ultrasound videos, which focuses on two aspects: eliminating spurious correlations caused by style and enhancing causal content correlations. Specifically, we introduce a novel Spurious Correlation Elimination (SCE) module to remove non-causal style effects by enforcing prediction invariance with style perturbations. Simultaneously, we propose a Causal Equivalence Consolidation (CEC) module to strengthen causal content correlation through adversarial optimization during content randomization. Simultaneously, we design a Causal Transition Augmentation (CTA) module to ensure smooth causal flow by integrating an auxiliary pathway with text prompts and connecting it through contrastive learning. The experimental results on our in-house carotid ultrasound video dataset achieved an accuracy of 86.93\%, demonstrating the superior performance of the proposed method. Code is available at \href{https://github.com/xielaobanyy/causal-imt}{https://github.com/xielaobanyy/causal-imt}.
Region-Based Optimization in Continual Learning for Audio Deepfake Detection
Dec 16, 2024



Rapid advancements in speech synthesis and voice conversion bring convenience but also new security risks, creating an urgent need for effective audio deepfake detection. Although current models perform well, their effectiveness diminishes when confronted with the diverse and evolving nature of real-world deepfakes. To address this issue, we propose a continual learning method named Region-Based Optimization (RegO) for audio deepfake detection. Specifically, we use the Fisher information matrix to measure important neuron regions for real and fake audio detection, dividing them into four regions. First, we directly fine-tune the less important regions to quickly adapt to new tasks. Next, we apply gradient optimization in parallel for regions important only to real audio detection, and in orthogonal directions for regions important only to fake audio detection. For regions that are important to both, we use sample proportion-based adaptive gradient optimization. This region-adaptive optimization ensures an appropriate trade-off between memory stability and learning plasticity. Additionally, to address the increase of redundant neurons from old tasks, we further introduce the Ebbinghaus forgetting mechanism to release them, thereby promoting the capability of the model to learn more generalized discriminative features. Experimental results show our method achieves a 21.3% improvement in EER over the state-of-the-art continual learning approach RWM for audio deepfake detection. Moreover, the effectiveness of RegO extends beyond the audio deepfake detection domain, showing potential significance in other tasks, such as image recognition. The code is available at https://github.com/cyjie429/RegO
Generalized Multimodal Fusion via Poisson-Nernst-Planck Equation
Oct 20, 2024



Previous studies have highlighted significant advancements in multimodal fusion. Nevertheless, such methods often encounter challenges regarding the efficacy of feature extraction, data integrity, consistency of feature dimensions, and adaptability across various downstream tasks. This paper proposes a generalized multimodal fusion method (GMF) via the Poisson-Nernst-Planck (PNP) equation, which adeptly addresses the aforementioned issues. Theoretically, the optimization objective for traditional multimodal tasks is formulated and redefined by integrating information entropy and the flow of gradient backward step. Leveraging these theoretical insights, the PNP equation is applied to feature fusion, rethinking multimodal features through the framework of charged particles in physics and controlling their movement through dissociation, concentration, and reconstruction. Building on these theoretical foundations, GMF disassociated features which extracted by the unimodal feature extractor into modality-specific and modality-invariant subspaces, thereby reducing mutual information and subsequently lowering the entropy of downstream tasks. The identifiability of the feature's origin enables our approach to function independently as a frontend, seamlessly integrated with a simple concatenation backend, or serve as a prerequisite for other modules. Experimental results on multiple downstream tasks show that the proposed GMF achieves performance close to the state-of-the-art (SOTA) accuracy while utilizing fewer parameters and computational resources. Furthermore, by integrating GMF with advanced fusion methods, we surpass the SOTA results.
MpoxMamba: A Grouped Mamba-based Lightweight Hybrid Network for Mpox Detection
Sep 06, 2024



Due to the lack of effective mpox detection tools, the mpox virus continues to spread worldwide and has once again been declared a public health emergency of international concern by the World Health Organization. Deep learning-based mpox detection tools are crucial to alleviate mpox outbreak. However, existing methods have difficulty in achieving a good trade-off between detection performance, parameter size, and model complexity, which is crucial for practical applications and widespread deployment, especially in resource-limited scenarios. Given that the success of Mamba in modeling long-range dependencies and its linear complexity, we proposed a lightweight hybrid architecture called MpoxMamba. MpoxMamba utilizes deep separable convolutions to extract local feature representations in mpox skin lesions, and greatly enhances the model's ability to model the global contextual information by grouped Mamba modules. Experimental results on two widely recognized mpox datasets demonstrate that MpoxMamba outperforms existing mpox detection methods and state-of-the-art lightweight models. We also developed a web-based online application to provide free mpox detection services to the public in the epidemic areas (http://5227i971s5.goho.co:30290). The source codes of MpoxMamba are available at https://github.com/YubiaoYue/MpoxMamba.
Frequency-mix Knowledge Distillation for Fake Speech Detection
Jun 14, 2024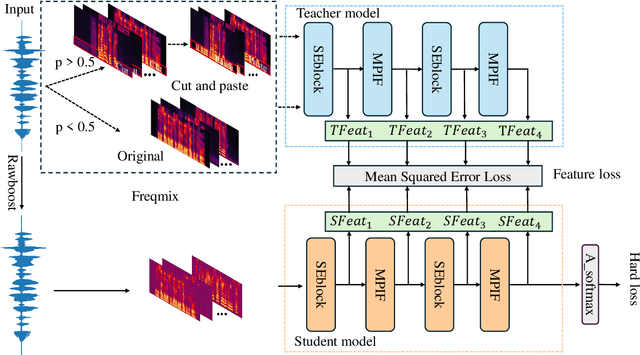
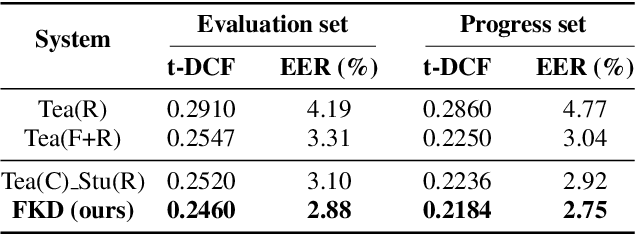
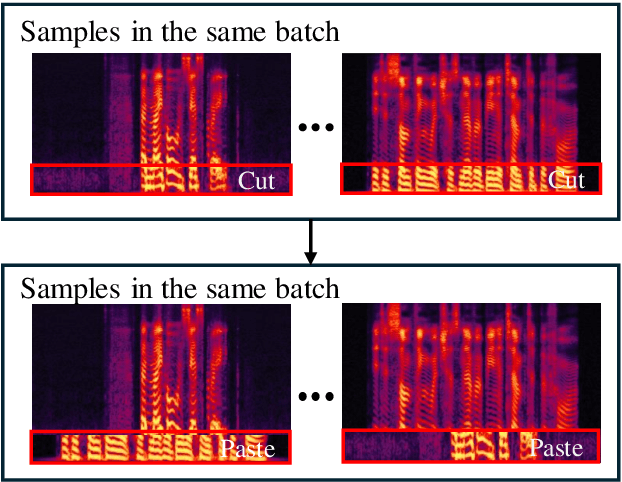
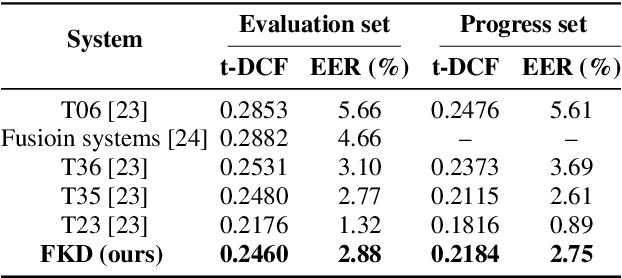
In the telephony scenarios, the fake speech detection (FSD) task to combat speech spoofing attacks is challenging. Data augmentation (DA) methods are considered effective means to address the FSD task in telephony scenarios, typically divided into time domain and frequency domain stages. While each has its advantages, both can result in information loss. To tackle this issue, we propose a novel DA method, Frequency-mix (Freqmix), and introduce the Freqmix knowledge distillation (FKD) to enhance model information extraction and generalization abilities. Specifically, we use Freqmix-enhanced data as input for the teacher model, while the student model's input undergoes time-domain DA method. We use a multi-level feature distillation approach to restore information and improve the model's generalization capabilities. Our approach achieves state-of-the-art results on ASVspoof 2021 LA dataset, showing a 31\% improvement over baseline and performs competitively on ASVspoof 2021 DF dataset.